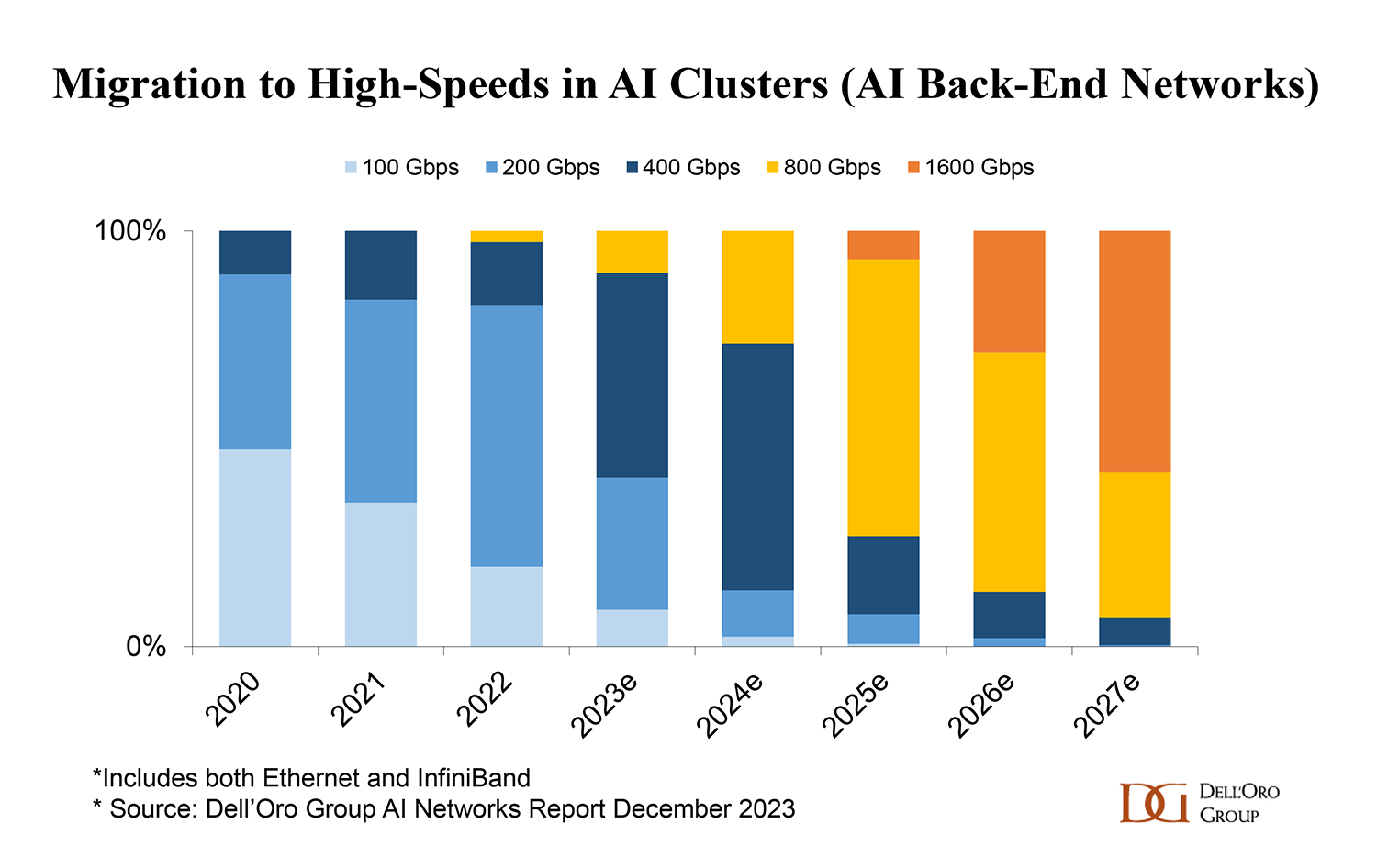
Market Overview
The worldwide data center capital expenditure (capex) grew by 4% in 2023, reaching $260 billion, with servers leading all technology areas in revenue (Figure 1). However, this growth rate marked a slowdown from the double-digit growth observed in the previous year. Despite lingering economic uncertainties, the market is poised for growth driven by advancements in accelerated computing for AI applications, and expanding data center footprint.
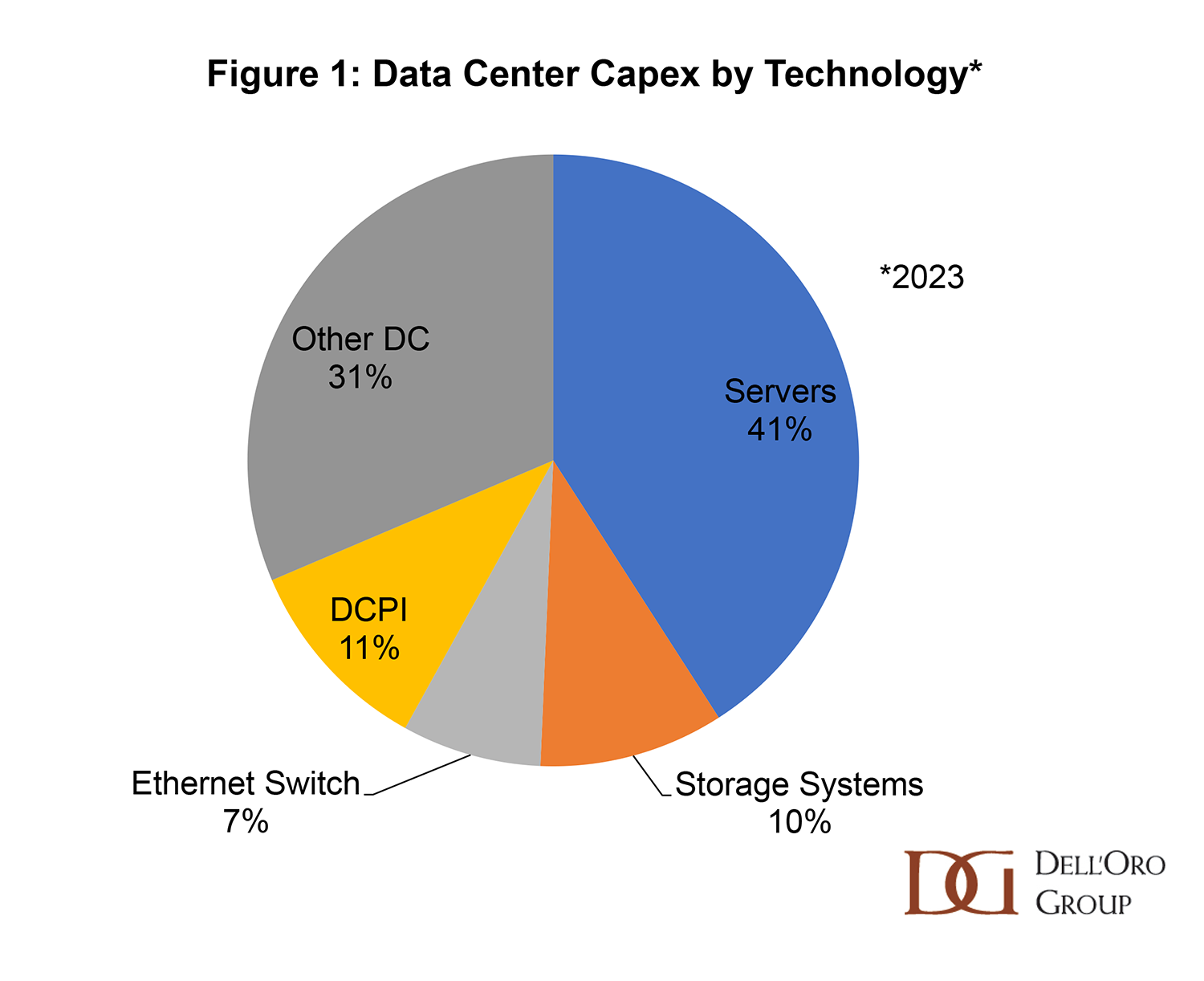
The growth varied across different categories of data center technology areas.
- IT infrastructure experienced a decline due to reduced investments in general-purpose servers and storage systems. This decline was attributed to supply issues that occurred in 2022, prompting enterprise customers and resellers to place excess orders, which led to inventory surges and subsequent corrections. Consequently, server shipments declined by 8% in 2023. The demand for general-purpose server and storage system components such as CPUs, memory, storage drives, and NICs, saw a sharp decline in 2023, as the major Cloud Service Providers (SPs) and server and storage system OEMs reduced component purchases in anticipation of weak system demand.
- In contrast, there was a shift in capex towards accelerated computing. Spending on accelerators, such as GPUs and other custom accelerators, more than tripled in 2023, as the major Cloud SPs raced to deploy accelerated computing infrastructure that is optimized for AI use cases ranging from recommenders to generative AI. Accelerated servers, although comprising a small share of total server volume, command a significant average selling price (ASP) premium, contributing significantly to revenue.
- Revenues for network infrastructure, consisting mostly of Ethernet switches, showed deceleration throughout 2023 as vendor fulfill back. Modest growth rates observed in the fourth quarter of 2023, reflecting a digestion cycle affecting various vendors and product segments.
- While the data center physical infrastructure (DCPI) revenues experienced robust double-digit growth in 2023, the market also decelerated in the fourth quarter of 2023. This slowdown was attributed to the diminishing impact of pandemic-induced digitalization and limited price realization from price increases implemented in 2022. However, emerging deployments associated with AI workloads, particularly in retrofitting power distribution and thermal management in existing facilities, provided a marginal contribution to growth.
Data center capex growth varied among customer segments, with Colocation SPs leading in growth due to ongoing momentum in DCPI and global data center footprint expansion. In the Top 4 US Cloud SP segment, Microsoft and Google increased data center investments, particularly in AI infrastructure, while Amazon, underwent a digestion cycle following pandemic-driven expansion. In contrast, the major Chinese Cloud SPs experienced declines in data center capex due to economic, regulatory, and demand challenges. Enterprise data center spending also declined modestly in 2023, reflecting weakening demand amid economic uncertainties and digestion.
Vendor Landscape
Below are some vendor highlights in the key technology areas we track:
- In the Server market, Dell led in revenue share, followed by HPE and IEIT Systems. Excluding white box server vendors, revenue for original equipment manufacturers (OEMs) declined by 10% in 2023, with lower server unit volumes attributed to economic uncertainties and excess channel inventory. However, some vendors experienced revenue growth through shifts in product mix towards accelerated platforms or general-purpose servers with the latest CPUs from Intel and AMD.
- The Storage System market witnessed a 7% decline in revenue in 2023, with Dell leading in revenue share, followed by Huawei and NetApp. Huawei was the only major vendor to achieve growth, driven by success in adopting the latest all-flash arrays among enterprise customers.
- In the Ethernet Data Center Switch market, Arista surpassed Cisco in the fourth quarter, although Cisco maintained its position as the market leader for the entirety of 2023. Cisco’s sales were boosted by substantial backlogged shipments earlier in the year. However, demand tapered off later as both cloud service providers and enterprise customers underwent a period of digestion. Meanwhile, Arista experienced remarkable revenue growth, outpacing the market due to its robust presence at Meta and Microsoft, both of which demonstrated significant network spending throughout 2023.
- In the DCPI market, Schneider Electric held onto the top market share ranking in 2023. Vertiv maintained the number two market position, but gained meaningful share and is now challenging Schneider Electric for the top market share position. Eaton rounds out the top three DCPI vendors. All three companies experienced double-digit revenue growth for the full year.
2024 Outlook
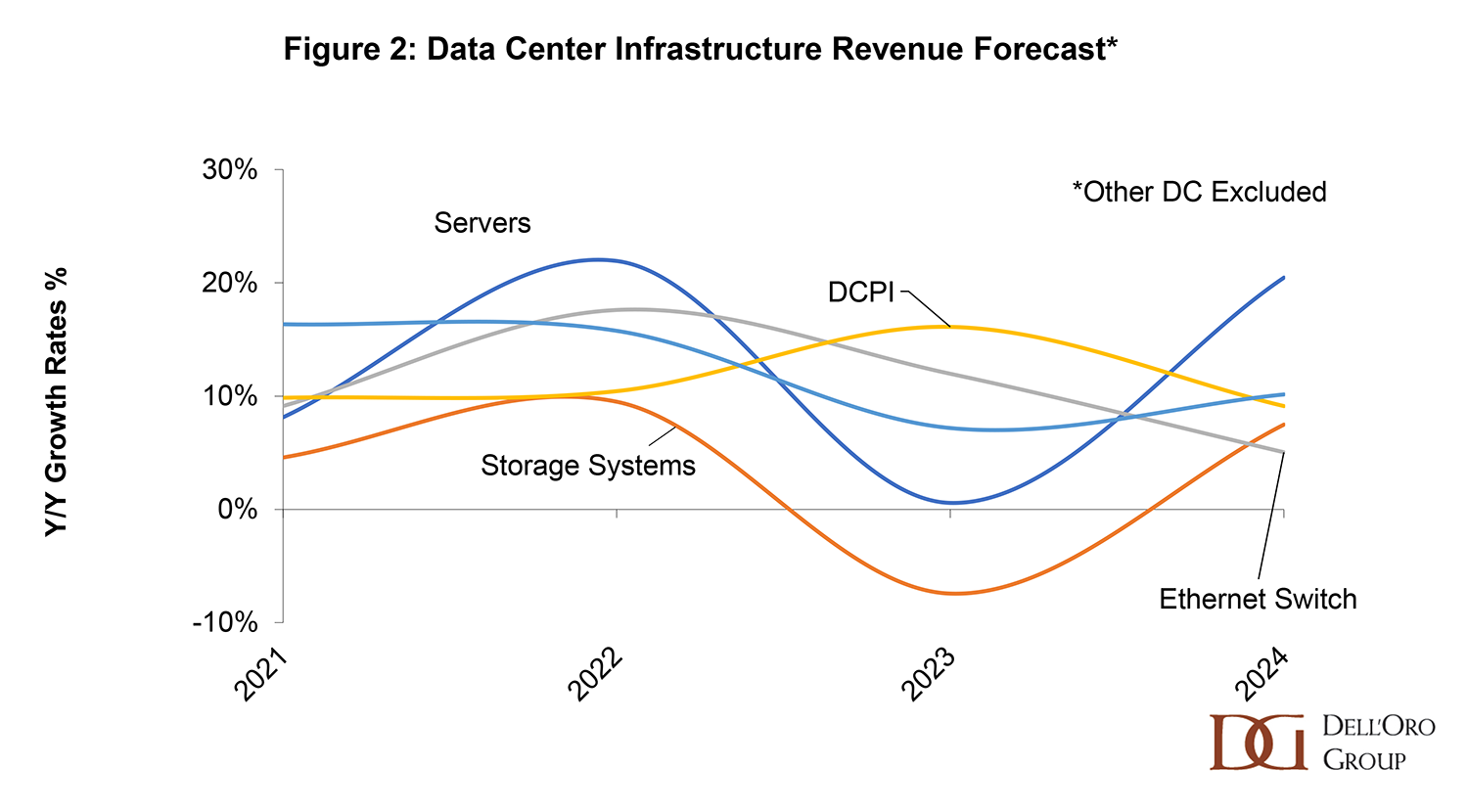 Looking ahead to 2024, the Dell’Oro Group forecasts a double-digit increase in worldwide data center capex, driven by increased server demand and average selling prices (Figure 2). Accelerated computing adoption is expected to continue, supported by new GPU platform releases from NVIDIA, AMD, and Intel. Growth in network infrastructure and DCPI revenues will depend on organic investments rather than supply chain-induced backlog or price increases. Recent recovery in server and storage component markets for CPUs, memory and storage drives is signaling the potential for increased system demand later this year. Dell’Oro Group projects moderate growth for the Top 4 US Cloud SPs in data center capex, while the Top 4 China-based cloud SPs are expected to undergo a cautious recovery. Additionally, enterprise and rest-of-cloud segments may be sensitive to macroeconomic conditions, with potential upside opportunities in AI-related investments.
Looking ahead to 2024, the Dell’Oro Group forecasts a double-digit increase in worldwide data center capex, driven by increased server demand and average selling prices (Figure 2). Accelerated computing adoption is expected to continue, supported by new GPU platform releases from NVIDIA, AMD, and Intel. Growth in network infrastructure and DCPI revenues will depend on organic investments rather than supply chain-induced backlog or price increases. Recent recovery in server and storage component markets for CPUs, memory and storage drives is signaling the potential for increased system demand later this year. Dell’Oro Group projects moderate growth for the Top 4 US Cloud SPs in data center capex, while the Top 4 China-based cloud SPs are expected to undergo a cautious recovery. Additionally, enterprise and rest-of-cloud segments may be sensitive to macroeconomic conditions, with potential upside opportunities in AI-related investments.