2023 witnessed a remarkable resurgence of the OFC conference following the pandemic. The event drew a significant turnout, and the atmosphere was buzzing with enthusiasm and energy. The level of excitement was matched by the abundance of groundbreaking announcements and product launches. Given my particular interest in the data center switch market, I will center my observations in this blog on the most pertinent highlights regarding data center networking.
The Bandwidth and Scale of AI Clusters Will Skyrocket Over the Next Few Years
It’s always interesting to hear from different vendors about their expectations for AI networks, but it’s particularly fascinating when Cloud Service Providers (SPs) discuss their plans and predictions regarding the projected growth of their AI workloads. This is because such workloads are expected to exert significant pressure on the bandwidth and scale of Cloud SPs’ networks, making the topic all the more astounding. At OFC this year, Meta portrayed their expectations of how their AI clusters in 2025 and beyond may look like. Two key takeaways from Meta’s predictions:
- The size and network bandwidth of AI clusters are expected to increase drastically in the future: Meta expects the size of its AI cluster will grow from 256 accelerators today to 4 K accelerators per cluster by 2025. Additionally, the amount of network bandwidth per accelerator is expected to grow from 200 Gbps to more than 1 Tbps, a phenomenal increase in just about three years. In summary, not only the size of the cluster is growing, but also the amount of compute network per accelerator is skyrocketing.
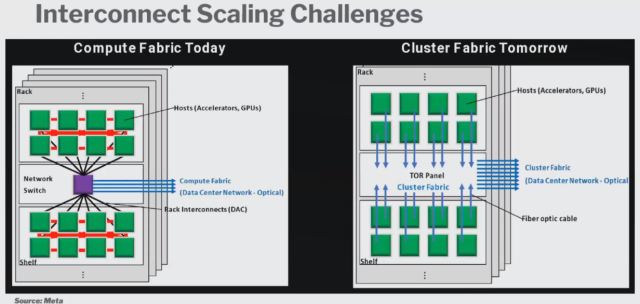
- The expected growth in the size of AI clusters and compute network capacity will have significant implications on how accelerators are currently connected: Meta showcased the current and potential future state of the cluster fabric. The chart below presented by Meta proposes flattening the network by embedding optics directly in every accelerator in the rack, rather than through a network switch. This tremendous increase in the number of optics, combined with the increase in network speeds is exacerbating the power consumption issues that Cloud SPs have already been battling with. We also believe that AI networks may require a different class of network switches purpose-built and designed for AI workloads.
Pluggable Optics vs. Co-packaged Optics (CPOs) vs. Linear Drive Pluggable Optics (LPOs)
Pluggable optics will be responsible for an increasing portion of the power consumption at a system level (more than 50% of the switch system power @ 51 .2 Tbps and beyond) and as mentioned above, this issue will only get exacerbated as Cloud SPs build their next-generation AI networks. CPOs emerged as an alternative technology that have the promise to reduce power and cost compared to pluggable optics. Below are some updates about the state of the CPO market:
- Cloud SPs are still on track to experiment with CPOs: Despite rumors that Cloud SPs are canceling their plans to deploy CPOs due to budget cuts, it appears that they are still on track to experiment with this technology. At OFC 2023, Meta reiterated their plans to consider CPOs in order to reduce power consumption from 20 pJ/bit to less than 5 pJ/bit using Direct Drive CPOs (Direct Drive CPOs eliminate the digital signal processors (DSPs)). It is still unclear, however, where exactly in the network they plan to implement CPOs or if it will be primarily used for compute interconnect.
- The ecosystem is making progress in developing CPOs but a lot remains to be done: There were several exciting demonstrations and product announcements at OFC 2023. For example, Broadcom showcased a prototype of its Tomahawk 5-based 51.2 Tbps “Bailly” CPO system, along with a fully functional Tomahawk 4-based 25.6 Tbps “Humboldt” CPO system that was announced in September 2022. Additionally, Cisco presented the power savings achieved with its CPO switch populated with CPO silicon photonic-based optical tiles driving 64×400 G FR4, as compared to a conventional 32-port 2x400G 1 RU switch. During our discussions with the OIF, we were provided with an update on the various standardization efforts taking place, including the standardization of the socket that the CPO module will go into. Our conversations with major players and stakeholders made it clear that significant progress has been made in the right direction. However, there is still much work to be done to reach the final destination, particularly in addressing serviceability, manufacturability, and testability issues that remain unsolved. Our CPO forecast published in our 5-year Data Center Forecast report January 2023 edition takes into consideration all of these challenges.
- LPOs present another alternative to explore: Andy Bechtolsheim of Arista has suggested LPOs as another alternative that may address some of the challenges of CPOs. The idea behind LPOs is to remove the DSP from pluggable optics, as the DSP drives about half of the power consumption and a large portion of the cost of 400 Gbps pluggable optics. By removing the DSP, LPOs would be able to reduce optic power by 50% and system power by up to 25% as Andy portrayed in the chart below.
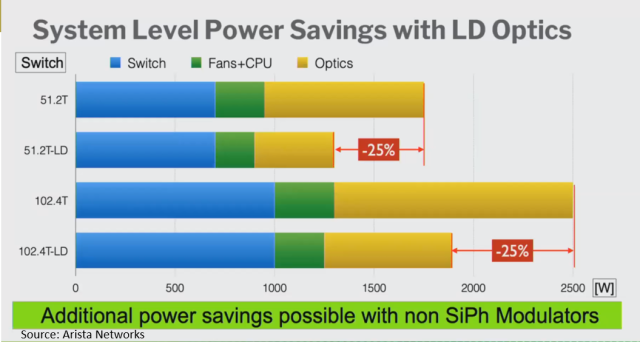
Additionally, other materials for Electric Optic Modulation (EOM) are being explored, which may offer even greater savings compared to silicon photonics. Although silicon photonics is a proven high-volume technology, it has high voltage and insertion loss, so exploring new materials such as TFLN may help lower power consumption. However, we would like to note that while LPOs has the potential to achieve power savings similar to CPOs, they put more stress on the electrical part of the switch system and require a high-performance switch SERDES and careful motherboard signal integrity design. We expect 2023 to be busy with measurement and testing activities for LPO products.
800 Gbps Pluggable Optics are Ready for Production Volume and 1.6 Tbps Optics are already in the Making
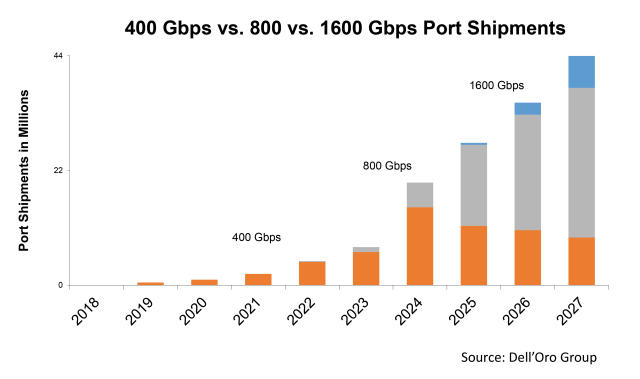
While we are excited about the aforementioned futuristic technologies that may take a few more years to mature, we are equally thrilled about the products on display at the OFC that will contribute to the market growth in the near future, such as the 800 Gbps optical pluggable transceivers, which were widely represented at the event this year. The timing was perfect, as it is aligned with the availability of 51.2 Tbps chips from various vendors, including Broadcom and Marvell. While 800 Gbps optics started shipping in 2022, more suppliers are currently sampling, and the volume production is expected to ramp up by the end of this year, as indicated in the chart below from our 5-year Data Center Forecast report January 2023 edition. In addition, several 1.6 Tbps optical components and transceivers based on 200 G per lambda were also introduced at OFC 2023, but we do not expect to see substantial volumes in the market before 2025/2026.
If you would like to hear more about our findings, please contact us at dgsales@delloro.com