I would like to share some initial thoughts about the groundbreaking announcement that HPE has entered into a definitive agreement to acquire Juniper for $14 B. My thoughts are mostly around the switch business of both firms. The WLAN and security aspects of the acquisition are covered by our WLAN analyst Sian Morgan and security analyst Mauricio Sanchez.
My initial key takeaways and thoughts on the potential upside and downside impact of the acquisition are:
Pros:
In the combined data center and campus switch market, Cisco has consistently dominated as the major incumbent vendor, with a 46% revenue share in 2022. HPE held the fourth position with approximately 5%, and Juniper secured the fifth spot with around 3%. A consolidated HPE/Juniper entity would climb to the fourth position, capturing 8% market share, trailing closely behind Huawei and Arista.
Juniper’s standout performer is undeniably their Mist portfolio, recognized as the most cutting-edge AI-driven platform in the industry. As AI capabilities increasingly define the competitive landscape for networking vendors, HPE stands to gain significantly from its access to the Mist platform. We believe that Mist played a pivotal role in motivating HPE to offer a premium of about 30% for the acquisition of Juniper. In other words, Juniper brings better “AI technology for networking” to the table.
In the data center space, HPE has predominantly focused on the compute side, with a relatively modest presence in the Data Center switch business (HPE Data Center switch sales amounted to approximately $150 M in 2022, in contrast to Juniper’s sales that exceeded $650 M). Consequently, we anticipate that HPE stands to gain significantly from Juniper’s data center portfolio. Nonetheless, a notable contribution from HPE lies in their Slingshot Fabric, which serves as a compelling alternative to InfiniBand for connecting large GPU clusters. In other words, HPE brings better “Networking technology for AI” to the table.
Juniper would definitely benefit from HPE’s extensive channels and go-to-market strategy (about 95% of HPE’s business goes through channels). Additionally, HPE has made great progress driving their as-a-service GreenLake solution. However, GreenLake has been so far mostly dominated by compute. With the Juniper acquisition, we expect to see more networking components pushed through GreenLake.
In campus and with the Mist acquisition in particular, Juniper has been focusing mostly on high-end enterprises whereas HPE has been playing mainly in commercial and mid-market. Therefore, from that standpoint, there should be a little overlap in the customer base and more of cross-selling opportunities.
Cons:
Undoubtedly, a significant challenge arises from the substantial product overlap, evident across various domains such as data center switching, campus switching, WLAN, and security. Observing how HPE navigates the convergence of these diverse product lines will be intriguing. Ideally, the merged product portfolio should synergize to bolster the market share of the consolidated entities. Regrettably, history has shown that not all product integration and consolidation meet that desired outcome.
[wp_tech_share]
We’ve been participating in the OCP Open Compute Project (OCP) Global Summit for many years, and while each year has brought pleasant surprises and announcements, as described in previous OCP blogs from2022and 2021, this year stands out in a league of its own. 2023 marks a significant turning point, notably with the advent of AI, which many speakers have referred to as a tectonic shift in the industry and a once-in-a-generation inflection point in computing and in the broader market. This transformation has unfolded within just the past few months, sparking a remarkable level of interest at the OCP conference. In fact, this year, the conference was completely sold out, demonstrating the widespread eagerness to grasp the opportunities and confront the challenges that this transformative shift presents to the market. Furthermore, at OCP 2023, there was a new track just to focus on AI. This year marks the beginning of a new era in the age of AI. AI is here! The race is on!
This new era of AI is marked and defined by the emergence of new generative AI applications and large language models. Some of these applications deal with billions and even trillions of parameters and the number of parameters seems to be growing 1000X every 2 to 3 years.
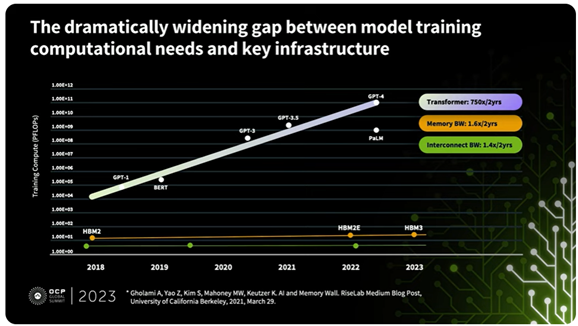
This complexity and size of the emerging AI applications dictate the number of accelerated nodes needed to run the AI applications as well as the scale and type of infrastructure needed to support and connect those accelerated nodes. Regrettably, as illustrated in the chart below presented by Meta at the OCP conference, a growing disparity exists between the requirements for model training and the available infrastructure to facilitate it.
This predicament poses the pivotal question: How can one scale to hundreds of thousands or even millions of accelerated nodes? The answer lies in the power of AI Networks purposively built and tuned for AI applications. So, what are the requirements that the AI Networks need to satisfy? To answer that question, let’s first look at the characteristics of AI workloads, which include but are not limited to the following:
Traffic patterns consist of a large portion of elephant flows
AI workloads require a large number of short remote memory access
The fact that all nodes transmit at the same time saturates links very quickly
The progression of all nodes can be held back by any delayed flow. In fact, Meta showed last year that 33% of elapsed time in AI/ML is spent waiting for the network.
Given these unique characteristics of AI workloads, AI Networks have to meet certain requirements such as high speed, low tail-latency, lossless and scalable fabrics.
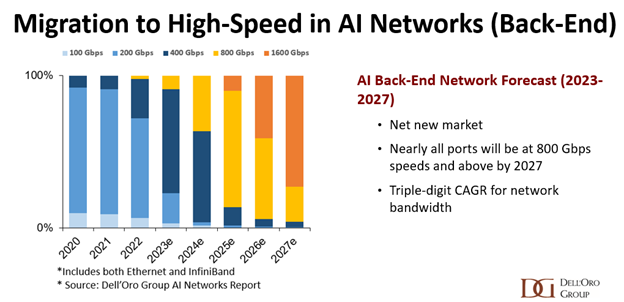
In terms of high-speed performance, the chart below, which I presented at OCP, shows that by 2027, we anticipate that nearly all ports in the AI back-end network will operate at a minimum speed of 800 Gbps, with 1600 Gbps comprising half of the ports. In contrast, our forecast for the port speed mix in the front-end network reveals that only about a third of the ports will be at 800 Gbps speed by 2027, while 1600 Gbps ports will constitute just 10%. This discrepancy in port speed mix underscores the substantial disparity in requirements between the front-end network, primarily used to connect general-purpose servers, and the back-end network, which primarily supports AI workloads.
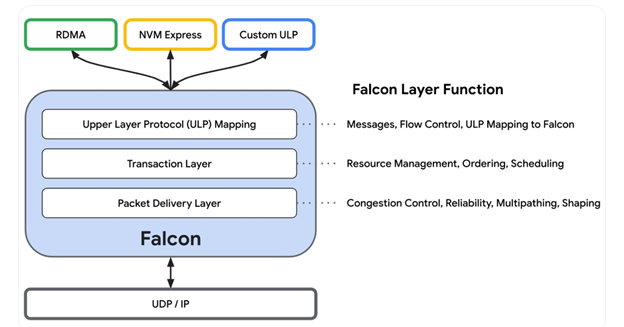
In the pursuit of achieving tail-latency and creating a lossless fabric, we are witnessing numerous initiatives aimed at enhancing Ethernet and modernizing it for optimal performance in AI workloads. For instance, the Ultra Ethernet Consortium (UEC) was established in July 2023, with the objective of delivering an open, interoperable, high-performance full-communications stack architecture based on Ethernet. Additionally, OCP has formed a new alliance to address significant networking challenges within AI cluster infrastructure. Another groundbreaking announcement from the OCP conference came from Google, who unveiled their opening of Falcon chips; a low-latency hardware transport, to the ecosystem through the Open Compute Project.
At OCP, there was a huge emphasis on adopting an open approach to address the scalability challenges of AI workloads, aligning seamlessly with the OCP 2023 theme: ‘Scaling Innovation Through Collaboration.’ Both Meta and Microsoft have consistently advocated, over the years, for community collaboration to tackle scalability issues. However, we were pleasantly surprised by the following statement from Google at OCP 2023: “A new era of AI systems design necessitates a dynamic open industry ecosystem”.
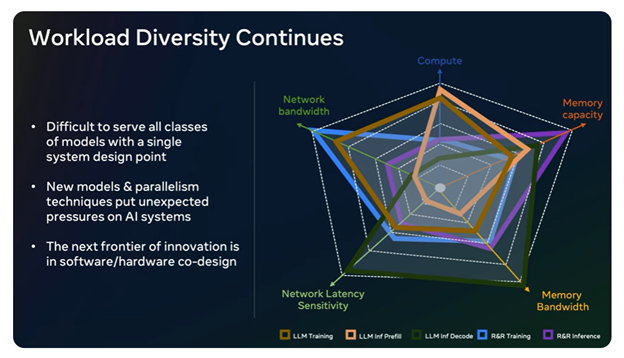
The challenges presented by AI workloads to network and infrastructure are compounded by the broad spectrum of workloads. As illustrated in the chart below showcased by Meta at OCP 2023, the diversity of workloads is evident in their varying requirements.
Source: Meta at OCP 2023
This diversity underscores the necessity of adopting a heterogeneous approach to build high-performance AI Networks and infrastructure capable of supporting a wide range of AI workloads. This heterogeneous approach will entail a combination of standardized as well as proprietary innovations and solutions. We anticipate that Cloud service providers will make distinct and unique choices, resulting in market bifurcation. In the upcoming Dell’Oro Group’s AI Networks for AI Workloads report, I delve into the various network fabric requirements based on cluster size, workload characteristics, and the distinctive choices made by cloud service providers.
Exciting years lie ahead of us! The AI journey is just 1% finished!
Save the date: Free OCP Educational Webinar on November 9, 8 AM PT, explores AI-driven network solutions, market potential, featuring Juniper Networks and Dell’Oro Group.Register now!
[wp_tech_share]
The rise of accelerated computing for applications such as AI and ML over the last several years has led to new innovations in the areas of compute, networking, and rack infrastructure. Accelerated computing generally refers to servers that are equipped with coprocessors such as GPUs and other custom accelerators. These accelerated servers are deployed as a system consisting of low-latency networking fabric, and enhanced thermal management to accommodate the higher power envelope.
Today, data centers account for approximately 2% of the global energy usage. While the latest accelerated server can consume up to 6kW of power each and may seem counterintuitive from a sustainability perspective, accelerated systems are actually more energy efficient compared to general-purpose servers when matched to the right mix of workloads. The advent of generative AI has significantly raised the threshold in compute and network demands, given that these language models consist of billions of parameters. Accelerators can help to train these large language models within a practical timeframe.
Deployment of these AI language models usually consists of two distinct stages: training and inference.
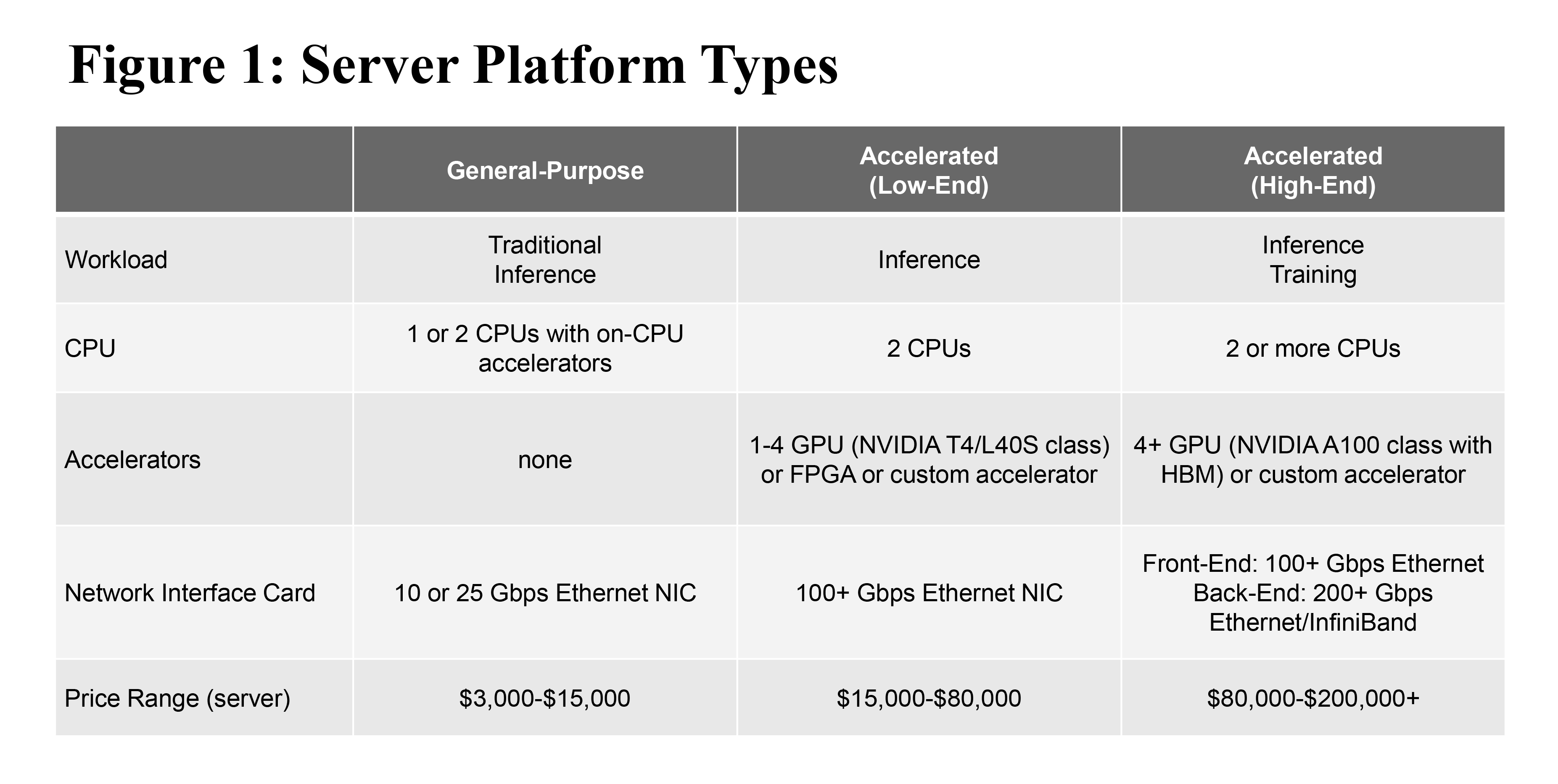
In AI training, data is fed into the model, so the model learns about the type of data to be analyzed. AI training is generally more infrastructure intensive, consisting of one to thousands of interconnected servers with multiple accelerators (such as GPUs and custom coprocessors) per server. We classify accelerators for training as “high-end” and examples include NVIDIA H100, Intel Gaudi2, AMD MI250, or custom processors such as the Google TPU.
In AI inference, the trained model is used to make predictions based on live data. AI inference servers may be equipped with discrete accelerators (such as GPUs, FPGAs, or custom processors) or embedded accelerators in the CPU. We classify accelerators for inference as “low-end” and examples include NVIDIA T4 or L40S. In some cases, AI inference servers are classified as general-purpose servers because of the lack of discrete accelerators.
Server Usage: Training vs. Inference?
A common question that has been asked is how much of the infrastructure, typically measured by the number of servers, is deployed for training as opposed to inference applications, and what is the adoption rate of each type of platform? This is a question that we have been investigating and debating, and the following factors complicate the analysis.
NVIDIA’s recent GPU offerings based on the A100 Ampere and H100 Hopper platforms are intended to support both training and inference. These platforms typically consist of a large array of multi-GPU servers that are interconnected and well-suited for training large language models. However, any excess capacity not used for training can be utilized towards inference workloads. While inference workloads typically do not require a large array of servers (although inference applications are increasing in size), inference applications can be deployed for multiple tenants through virtualization.
The latest CPUs from Intel and AMD have embedded accelerators on the CPU that are optimized for inference applications. Thus, a monolithic architecture without discrete accelerators is ideal as capacity can be shared by both traditional and inference workloads.
The chip vendors also sell GPUs and other accelerators not as systems but as PCI Express add-in cards. One or several of these accelerator add-in cards can be installed by the end-user after the sale of the system.
Given that different workloads (training, inference, and traditional) can be shared on one type of system, and that end-users can reconfigure the systems with discrete accelerators, it becomes less meaningful to delineate the market purely by workload type. Instead, we segment the market by three distinct types of server platform types as defined in Figure 1.
Looking ahead we expect continued innovation and new architectures to support the growth of AI. More specialized systems and processors will be developed that will enable more efficient and sustainable computing. We also expect the vendor landscape to be more diversified, with compelling solutions from the vendors and cloud service providers to optimize the performance of each workload.
Artificial intelligence (AI) is currently having a profound impact on the data center industry. This impact can be attributed to OpenAI’s launch of ChatGPT in late 2022, which rapidly gained popularity for its remarkable ability to provide sophisticated and human-like responses to queries. As a result, generative AI, a subset of AI technology, became the focal point of discussions across industry events, earnings presentations, and vendor ecosystem discussions in the first half of 2023. The excitement is warranted, as generative AI has already caused tens of billions of dollars of investments, and is forecast to continue to lift Data Center Capex to over $500 Billion by 2027. However, due to the significant expansion of computing power required for training and deploying large language models (LLMs) that support generative AI applications, it will require architectural changes for data centers.
While the hardware required to support such AI applications is new to many, there is a segment of the data center industry that has already been deploying such infrastructure for years. This segment is often known as the high-performance computing (HPC) or supercomputing industry. Historically, this market segment has primarily been supported by governments and higher education to deploy some of the world’s most complex and sophisticated computer systems.
What generative AI is doing that is new is proliferating AI applications and the infrastructure to support them, to the much wider enterprise and service provider markets. Learning from the HPC industry gives us an idea of what that infrastructure may start to look like.
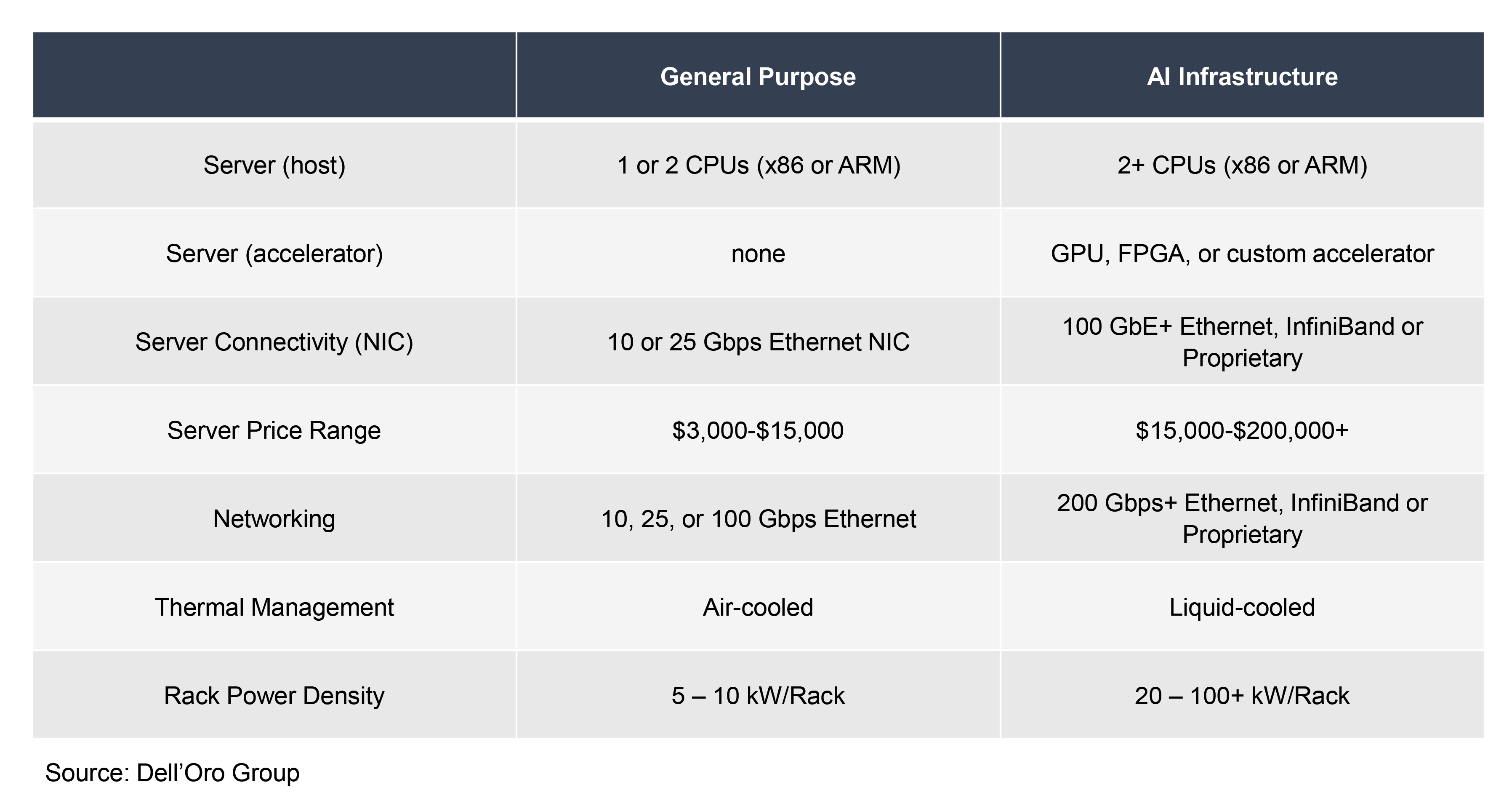
Figure 1: AI Hardware Implications
AI Infrastructure Needs More Power and Liquid Cooling
To summarize the implications shown in Figure 1, AI workloads will require more computing power and higher networking speeds. This will lead to higher rack power densities, which has significant implications for Data Center Physical Infrastructure (DCPI). For facility power infrastructure, also referred to as grey space, architectural changes are expected to be limited. AI workloads should increase demand for backup power (UPS) and power distribution to the IT rack (Cabinet PDU and Busway), but it won’t mandate any significant technology changes. Where AI Infrastructure will lead to a transformational impact on DCPI is in a data center’s white space.
First, due to the substantial power consumption of AI IT hardware, there is a need for higher power-rated rack PDUs. At these power ratings, the costs associated with potential failures or inefficiencies can be high. This is expected to push end users towards the adoption of intelligent rack PDUs, with the ability to remotely monitor and manage power consumption and environment factors. These rack PDUs cost many magnitudes higher than basic rack PDUs, which don’t give an end user the ability to monitor or manage their rack power distribution.
Even more transformative for data center architectures is the necessity of liquid cooling to manage higher heat loads produced by next-generation CPUs and GPUs to run AI workloads. Liquid cooling, both direct liquid cooling and immersion cooling, has been growing in adoption in the wider data center industry, which is expected to accelerate alongside the deployment of AI infrastructure. However, given the historically long runway associated with adopting liquid cooling, we anticipate that the influence of generative AI on liquid cooling will be limited in the near term. It remains possible to deploy the current generation of IT infrastructure with air-cooling but at the expense of hardware utilization and efficiency.
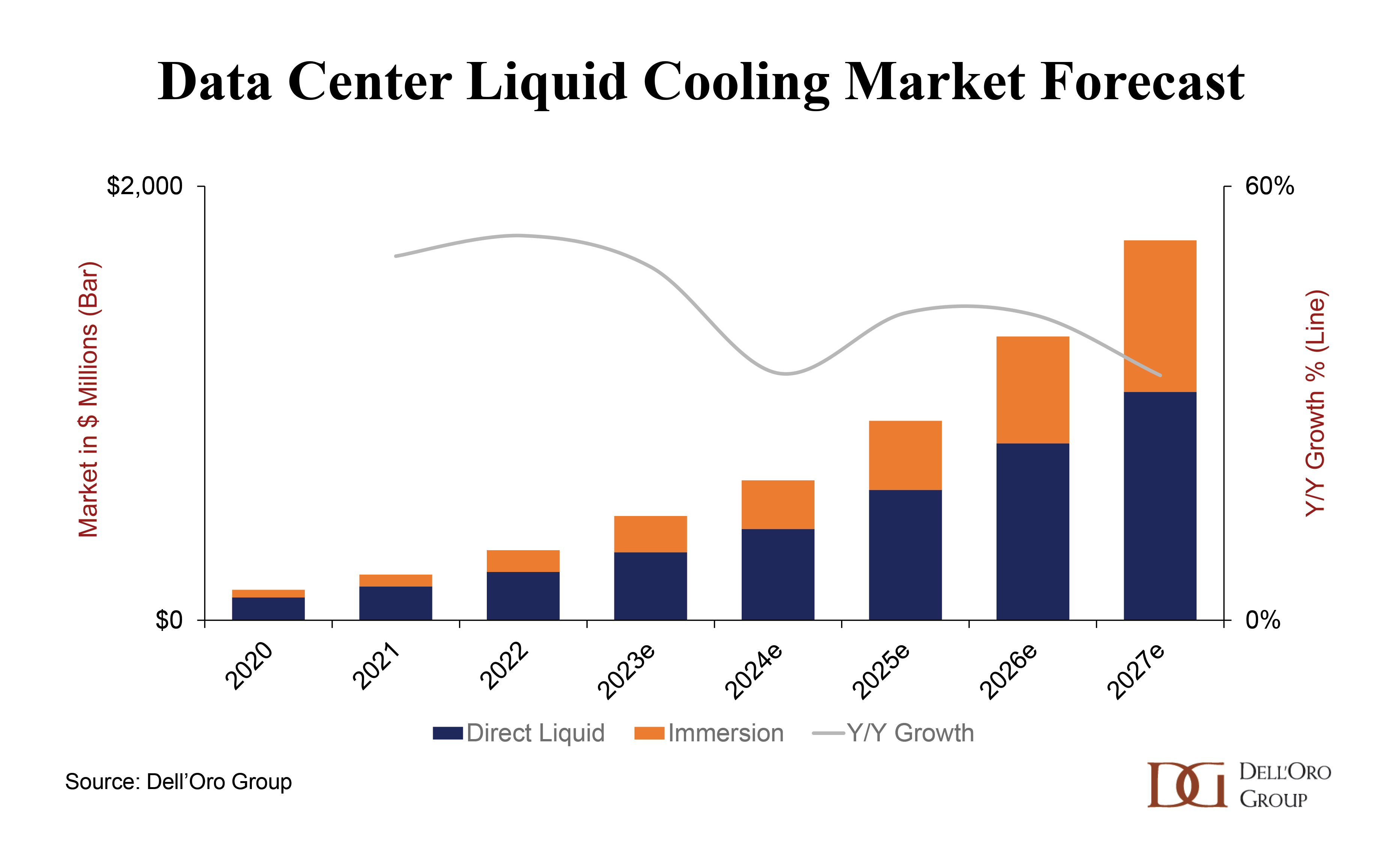
To address this challenge, some end-users are retrofitting their existing facilities with closed-loop air-assisted liquid cooling systems. Such infrastructure can be a version of a rear door heat exchanger (RDHx) or direct liquid cooling that utilizes a liquid to capture the heat generated within the rack or server, and reject it at the rear of the rack or server, directing it into a hot aisle. This design allows data center operators to leverage some advantages of liquid cooling without significant investments to redesign a facility. However, to achieve the desired efficiency of AI hardware at scale, purpose-built liquid-cooled facilities will be required. We expect the current interest in liquid cooling will start to materialize in deployments by 2025, with liquid cooling revenues forecast to approach $2 Billion by 2027.
Power Availability May Disrupt the AI Hype
Plans to incorporate AI workloads in future data center construction are already materializing. This was the primary reason for our recent upward revision to our Data Center Physical Infrastructure market 5-Year outlook, with revenue growth now forecast to grow at a 10% CAGR to 2027. But, despite all the prospective market growth AI workloads are expected to generate for the data center industry, there are some notable factors that could slow that growth. At the top of that list is power availability. The Covid-19 pandemic accelerated the pace of digitalization, spurring a wave of new data center construction. However, as that demand materialized, supply chains struggled to keep up, resulting in data center physical infrastructure lead times beyond a year at their peak. Now, as supply chain constraints are easing, DCPI vendors are working through elevated backlogs and starting to reduce lead time.
Yet, demand for AI workloads is forming another wave of growth for the data center industry. This double-shot of growth has generated a discrepancy between the growing energy needs of the data center industry and the pace at which utilities can supply power to the desired locations. Consequently, this is leading to data center service providers to explore a “Bring Your Own Power” model as a potential solution. While the feasibility of this model is still being determined, data center providers are thirsty for an innovative approach to support their long-term growth strategies, with the surge in AI Workloads being a central driver.
As the need for more DCPI is balanced against available power, one thing is clear — AI is ushering in a new era for DCPI. In this era, DCPI will not only play a critical role in enabling data center growth but will also define performance, cost and help achieve progress towards sustainability. This is a distinct shift from the historical role DCPI played, particularly compared to the industry nearly a decade ago when DCPI was almost an afterthought.
With this tidal wave of AI growth quickly approaching, it’s critical to address DCPI requirements within your AI strategy. Failing to do so might result in AI IT hardware with nowhere to get plugged in.
[wp_tech_share]
Recently, the U.S. Department of Energy (DOE) announced $40 million in funding to accelerate innovation in data center thermal management technologies intended to help reduce carbon emissions. The funding was awarded to 15 projects, ranging in value from $1.2 to $5 Million, to universities, labs, and enterprises in the data center and aerospace industries. It will likely take 1 to 3 years for these projects to start impacting the data center industry, but following the money can provide an early indication on the potential direction of future data center thermal management technologies.
Before we assess what we can learn from the selected projects, it’s important to understand why the DOE is investing in the development of next-generation data center thermal management. It’s simple –Thermal management can consume up to 40% of a data centers’ overall energy use, second most to compute. This energy is consumed in the process of capturing the heat generated by the IT infrastructure and rejecting it into the atmosphere. The data center industry has been optimizing today’s air-based thermal management infrastructure, but with processor TDPs rising (think CPUs and GPUs generating more heat), liquid is likely required to achieve the performance and efficiency standards desired by data center operators and regulators in the near future. The type of liquid and how it is applied to thermal management has divided the data center industry on the best path forward. The COOLERCHIPS program provides a unique lens into the developments happening behind the scenes that may impact the direction of future liquid cooling technologies.
To assess the impact of the COOLERCHIPS project awards, each of the 15 projects was segmented by the type of thermal management technology and the heat capture medium. The projects were placed into the following categories (Not all projects could be applied to both segments):
Funding by Technology (n=14)
Direct Liquid Cooling: A cold plate attached to a CPU with a CDU managing the secondary fluid loop.
Immersion Cooling: A server immersed in fluid within a tank or chassis.
Software: Software tools used to design, model, and evaluate different data center thermal management technologies.
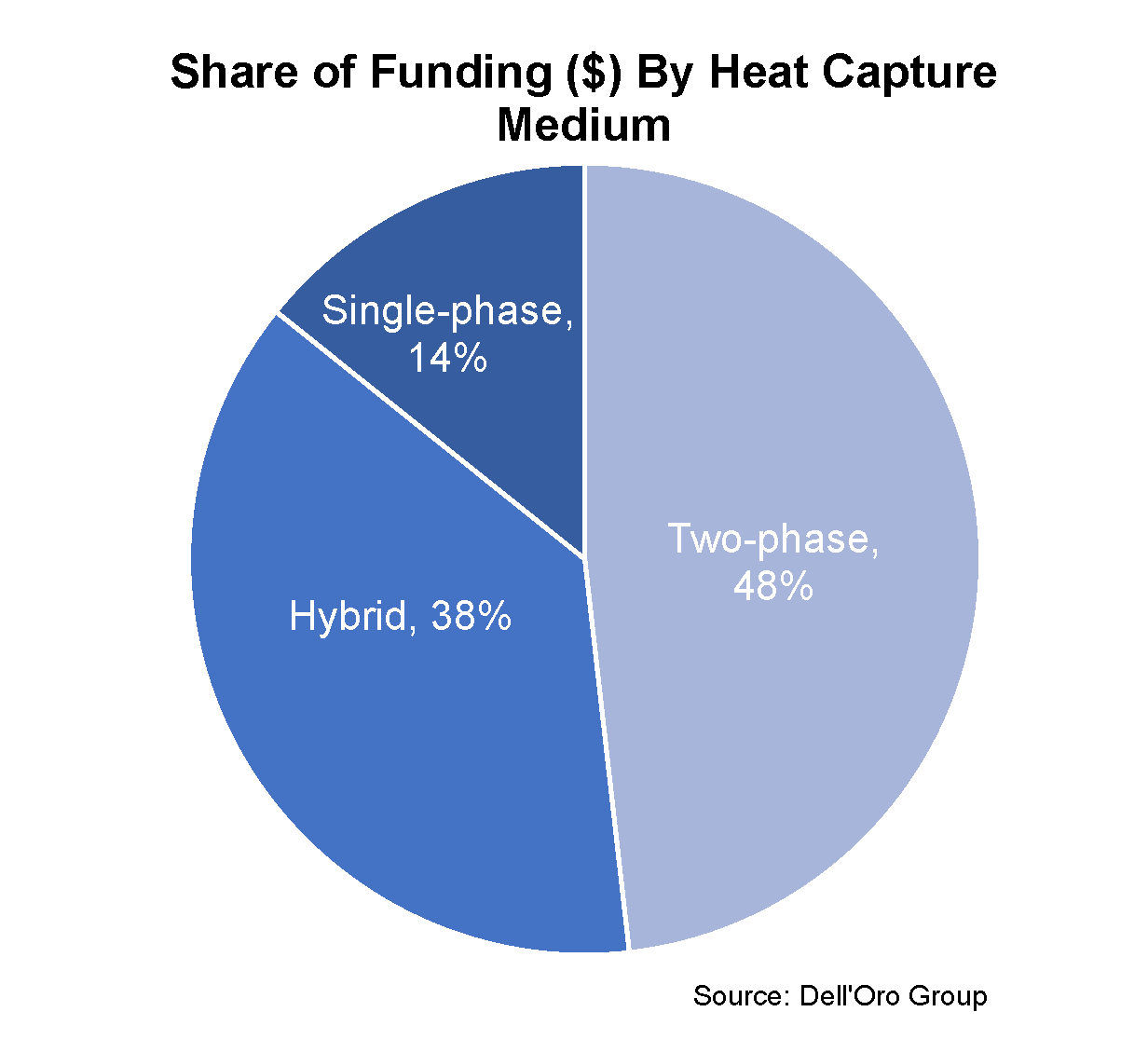
Funding by Heat Capture Medium (n=10)
Single-phase: A fluid that always remains a liquid in the heat capture and transfer process of data center liquid cooling.
Two-phase: A fluid that boils during the heat capture process to produce a vapor that transfers the heat to a heat exchanger, where it condenses back into a fluid.
Hybrid: Combined use of a single-phase or two-phase fluid and air to capture and transfer heat in the thermal management process.
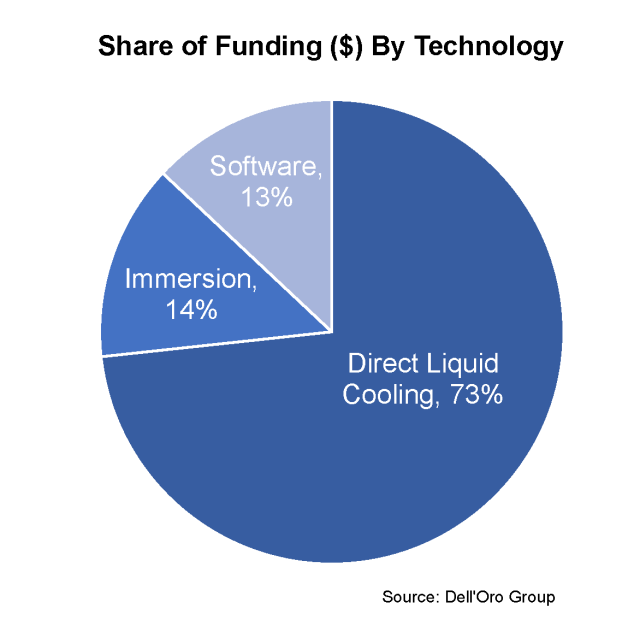
The results for funding by technology showed that direct liquid cooling accounted for 73% of awarded funds, immersion cooling 14%, and software 13%. This isn’t a particular surprise, given that direct liquid cooling is more mature than Immersion cooling in the data center industry, primarily due to the use of direct liquid cooling in high-performance computing. Additionally, the planning, design and operational changes in implementing immersion cooling have proved to be a bigger hurdle for some end-users than originally anticipated. Despite only receiving 14% of the awarded funds, there is still significant maturation occurring with immersion cooling as the installed base grows among a variety of end users. Lastly, software rounded out the projects with 13% of the awarded funds. This was a welcome addition, as software plays a critical role in thermal management design and evaluation when comparing the use of different thermal management technologies in different scenarios. Environmental factors such as temperature and humidity, computational workloads, and prioritization of sustainability can all influence which technology choice is best. Software must be utilized to align an end users’ priorities with the technology best suited to reach those goals.
The results for funding by heat capture medium showed that two-phase solutions accounted for 48% of the awarded funds, hybrid solutions 38%, and single-phase solutions 14%. It was surprising to see two-phase solutions garner the most funding since the significant majority of data center liquid cooling today is single-phase solutions. Between 3M announcing their exit of PFAS manufacturing by 2025 and evolving European F-Gas regulations, certain manufactured fluids have been under pressure. But that may be the very reason two-phase solutions were awarded such funding – They may a play critical role in thermal management as CPU and GPU roadmaps reach and surpass 500 watt TDPs in the coming years. Inversely, it’s possible that the level of maturity in single-phase solutions is what limited the awards to only 14% of funding. Furthermore, single-phase solutions aren’t always a 100% heat capture solution, so it makes sense that hybrid solutions that bring air and liquid technologies together that do capture 100% of the heat, received more funding. Afterall, end users are increasingly interested in holistic solutions when it comes to the never-ending cycle of deploying more computing power.
Based on these results conclude data center thermal management is headed towards two-phase direct liquid cooling solutions in the medium to long term. However, it’s important to remember the maturity that is already emerging in single-phase liquid cooling solutions. This maturity is what has driven the data center liquid cooling market to account for $329 million in 2022, which is forecast to reach $1.7 billion by 2027. The liquid cooling technology and fluids will most certainly evolve over the coming years, with investments from the DOE, among many others, helping shape that direction. But most importantly, the COOLERCHIPS project awards aren’t about closing doors to solutions that already exist, but opening doors to new technologies to give us more choices for efficient, reliable and sustainable thermal management solutions in the future.